Control de versiones usando GitLab (II)
En la entrada anterior vimos las ventajas de usar un control de versiones cuando programamos aplicaciones. También revisamos por encima los conceptos básicos que son necesarios para trabajar con Git. La explicación está simplificada para que sea más sencilla de entender. En este punto la duda era si seguir explicando el funcionamiento de Git de forma local o usando GitLab. Por claridad he elegido la segunda opción ya que nos permite ver el flujo de trabajo que debemos seguir para programar. Se pueden conseguir los mismos resultados de forma local pero perderíamos la visión extra que nos da GitLab. Para usar GitLab necesitamos registrarnos, es un proceso rápido y gratuito. Si os preocupa la privacidad podéis usar GitLab de forma local. En ese caso os haría falta una máquina virtual y seguir unas instrucciones. De momento no entraré en ese punto pero puedo hacer una entrada relacionada con la instalación de GitLab si hay interés.
Logo de GitLab
Cuenta de GitLab
El primer paso es iniciar sesión en GitLab. Podemos crear una cuenta o iniciar sesión con cualquiera de las cuentas soportadas (Google, GitHub, etc.). Os recomiendo crear una cuenta nueva. Inicialmente la página está en inglés pero se puede configurar para que muestre toda la información en castellano.
Inicio de sesión en GitLab
En la parte superior tenemos la información básica. Podemos ver los proyectos que tenemos, los grupos (agrupaciones de proyectos) y otros elementos relacionados como la actividad de los proyectos. En la actividad podemos ver toda la información relacionada con los proyectos que tenemos. Por ejemplo, podemos ver un resumen con los commits, los issues o los merges (integración del código de una rama en otra).

Actividad en GitLab
Creación de un proyecto
Para crear un proyecto pulsamos en el botón con el símbolo “+” y elegimos la primera opción. De momento usaremos la primera pestaña ya que la configuración es más sencilla. Otras opciones nos permiten usar una plantilla o importar un proyecto de otro control de versiones. El primer paso es escribir el nombre del proyecto. Aunque se puede cambiar el nombre del proyecto más adelante, tiene algunas consecuencias que pueden afectar al uso del repositorio. Os recomiendo pensar bien el nombre y dejarlo bien definido en este punto.
La URL del proyecto siempre empezará con https://gitlab.com. Después tenemos dos opciones. La primera es que aparezca el nombre del usuario. En este caso el proyecto estaría asociado a nuestra cuenta. Si pertenecemos a un grupo, es posible crearlo dentro del grupo. Al hacerlo de esta forma, el proyecto estaría asociado a todos los miembros del grupo. Si habéis creado la cuenta en GitLab sólo tendréis la primera opción. La descripción no es obligatoria pero ayudará a conocer la finalidad del proyecto.
Por último tenemos el nivel de visibilidad. Define si el proyecto es privado (sólo lo podemos ver nosotros) o público (cualquier lo puede ver y participar). Si estáis haciendo pruebas puede ser más sencillo mantener el proyecto privado. Después ya se puede hacer público si lo necesitamos. Marcaremos también la opción de inicializar el repositorio. Por comodidad, crearemos el repositorio en GitLab y después lo clonaremos (descargaremos) para trabajar en local.

Creación de un proyecto nuevo en GitLab
Al crear el proyecto llegaremos a la siguiente pantalla. Podemos pulsar en las ‘x’ que hay para tener más espacio en la pantalla.

Proyecto creado en GitLab
Flujo de trabajo con GitLab
GitLab tiene muchas opciones y puede resultar un poco amenazante al principio. Veremos el flujo básico para programar y las opciones necesarias según nos hagan falta. Si explico todas las funciones de golpe, lo más probable es que salgáis corriendo. La parte central es el gestor de incidencias (issues). Una incidencia es tanto una función nueva como un reporte de bug. Tiene que incluir toda la información necesaria para realizar la tarea. La incidencia actúa como contrato y dice lo que hay que hacer. Si hay un fallo y no tiene una incidencia creada, a efectos de programación no existe. En principio cualquier usuario puede crear incidencias, siempre que lo permita la configuración del proyecto, pero es tarea del programador aceptarla o no.

Gestor de incidencias en GitLab
Ya depende del proyecto, pero normalmente las incidencias se escriben en inglés. Antes de crear una incidencia conviene comprobar el idioma de las incidencias que ya están reportadas. Una incidencia tiene un título y una descripción. La descripción se puede formatear usando Markdown. Aquí vemos varios campos extras que están relacionados con la incidencia. El primero es la persona que tiene asignada la incidencia para trabajar. Un milestone cuenta como una versión de software. El milestone tiene asociada una fecha estimada y un conjunto de incidencias que deben entrar. Después tenemos las etiquetas (labels). Permite asignar etiquetas comunes a un issue de forma que se pueda acceder de forma más rápida a todos los issues relacionados. El peso (weight) permite indicar la complejidad que tiene un issue. Por último la fecha define el momento en el que debería estar finalizada la incidencia.

Crear una nueva incidencia
Creación de una rama
Una vez hemos definido una incidencia, el siguiente paso es crear una rama de trabajo. Se puede trabajar directamente en master o develop, si no os importa liberar el caos. Normalmente se crea una rama nueva de trabajo tomando como origen una rama inicial. De forma ideal deberíamos tener separadas las ramas de master y develop. Para este ejemplo tomaremos como origen master.
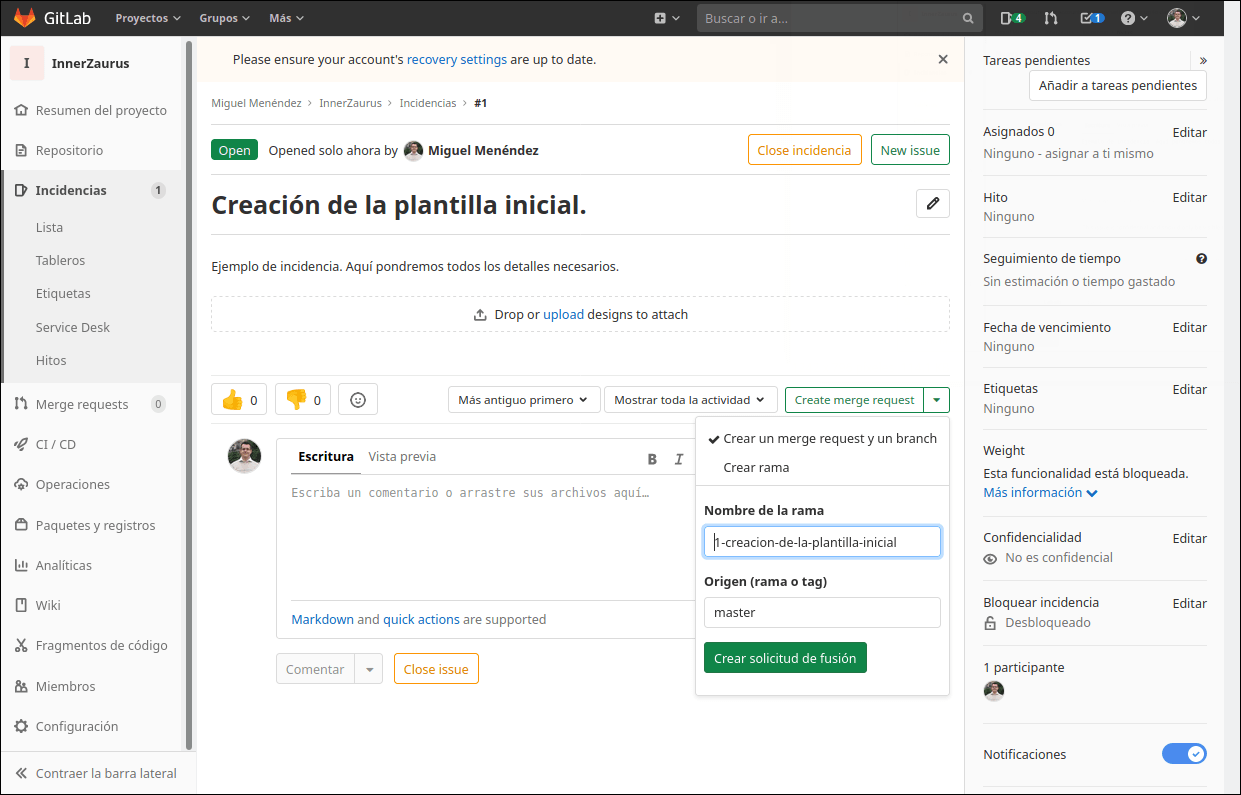
Creación de una rama en GitLab
Se creará la rama de trabajo y sobre ella haremos todos los cambios. Una vez los tenemos, integraremos el código de la rama de trabajo en master y pasaremos al siguiente issue. Este es el flujo de trabajo que deberíamos de seguir al programar. Primero se crea la incidencia, luego la rama y por último se empieza a picar el código. Si nos saltamos los pasos podemos tener problemas en el futuro.
Conclusiones
Hemos visto en esta entrada el flujo de trabajo que deberíamos seguir en GitLab. Es cierto que añade unos pasos extras que aparentemente no nos aportan mucho, pero al seguirlos tendremos toda la información organizada. Un programador puede recordar bien los cambios cuando han pasado unos días desde que los realizó. La cosa se complica cuando han pasado un par de semanas y ha ido añadiendo nuevas funciones en los mismos archivos. Al final llega un momento que no es tan sencillo recordar el momento en el que se hizo un cambio ni lo que se modificó. Estos problemas desaparecen usando Git junto con GitLab. Si en el proyecto intervienen muchas personas, la complejidad no aumenta ya que todo es más sencillo de seguir.
En la siguiente entrega usaremos el repositorio que hemos creado de forma local. Añadiremos los cambios y los sincronizaremos con GitLab. Por último revisaremos la incidencia y si todo es correcto, la integraremos en la rama principal del programa.
 mimecar
mimecar UBports
UBports
Dejar un comentario
¿Quieres unirte a la conversación?Siéntete libre de contribuir!